How to get Text Parser to produce an output value¶
Case scenario example, you would like to parse the filetype of a file document "filename.docx" and the extension of the filename always varies from docx to pdf to CSV.
The expression that you may choose to use in this case is \..+
If you were to use this on regex expression on regex101.com you will rightly find that you will get a match a full match.
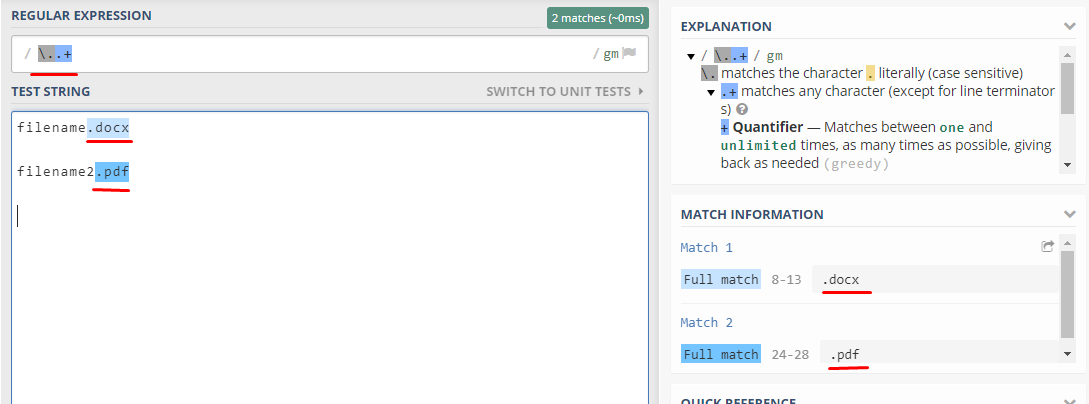
As you will notice on the image above that the file extension was correctly matched as shown in the image above and if you take and try to implement this in your text parser:
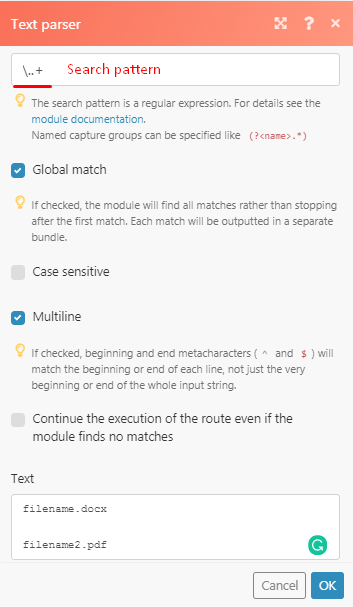
You will find that you will not get a match as shown in the image below.
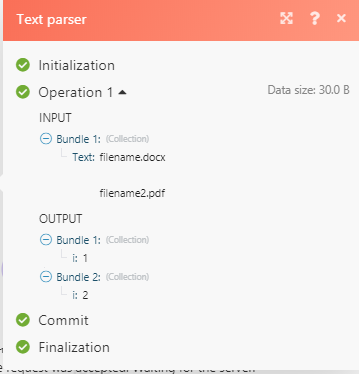
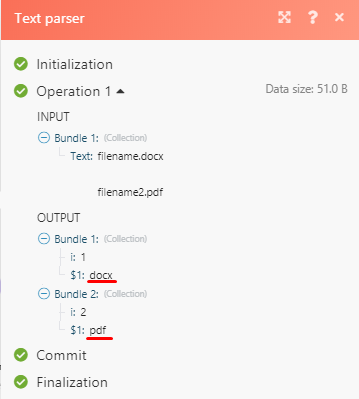
The reason for this is that the i shows only the number of matches per match so in this case, we have 2 matches henceforth after the i there is a numerical value 1 and 2. The use case for this is that should you ever need to match or pass data through a filter only the second matched value you can specify which value that is represented by the numerical value.
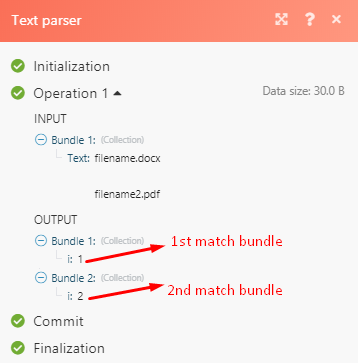
To be able to get the match values that you require to add brackets to the part that you wish to parse for example if one wishes to extract from "filename.docx" - "docx" only then according to the regex expression we are using for this case scenario the brackets should be applied on \.(.+) this will capture the docx place it in a group and leave the "." out of it.
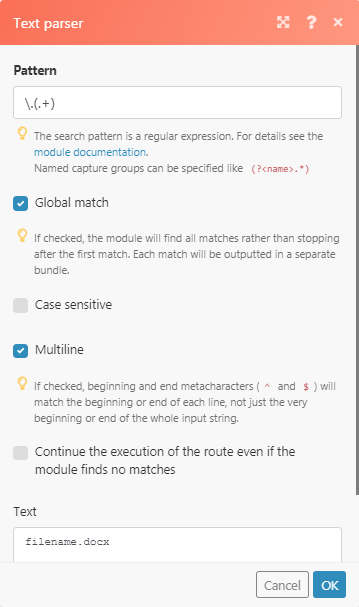
The output shown in the picture below, you will notice that the capturing group will match any character (except for line terminators).
Another workaround thats also incorporates regex is using the replace function:
1 | |
Then replace abcdefghijklmno pqr stuvw xyz.docx with your actual filename variable.