Google Cloud Speech¶
Getting Started with Google Cloud Speech¶
Prerequisites
-
A Google Cloud Platform account
-
Google Cloud Credentials (OAuth Client ID and Client Secret)
-
Enabled Google Speech-to-Text service
In order to use Google Cloud Speech with Ibexa Connect, it is necessary to have a Google Cloud Platform account. If you do not have one, you can create an account on the Google Cloud Speech-to-text website.
Connecting Google Cloud Platform to Ibexa Connect¶
To connect Google Cloud Speech to Ibexa Connect you must connect your Google Cloud Platform account to Ibexa Connect. To do so, you must provide the Client ID and Client Secret.
How to retrieve the OAuth Client ID and Client Secret¶
-
Open the Google Cloud Console.
-
Create a new project.
-
Go to the APIs & Services > Credentials and Configure the OAuth consent screen.
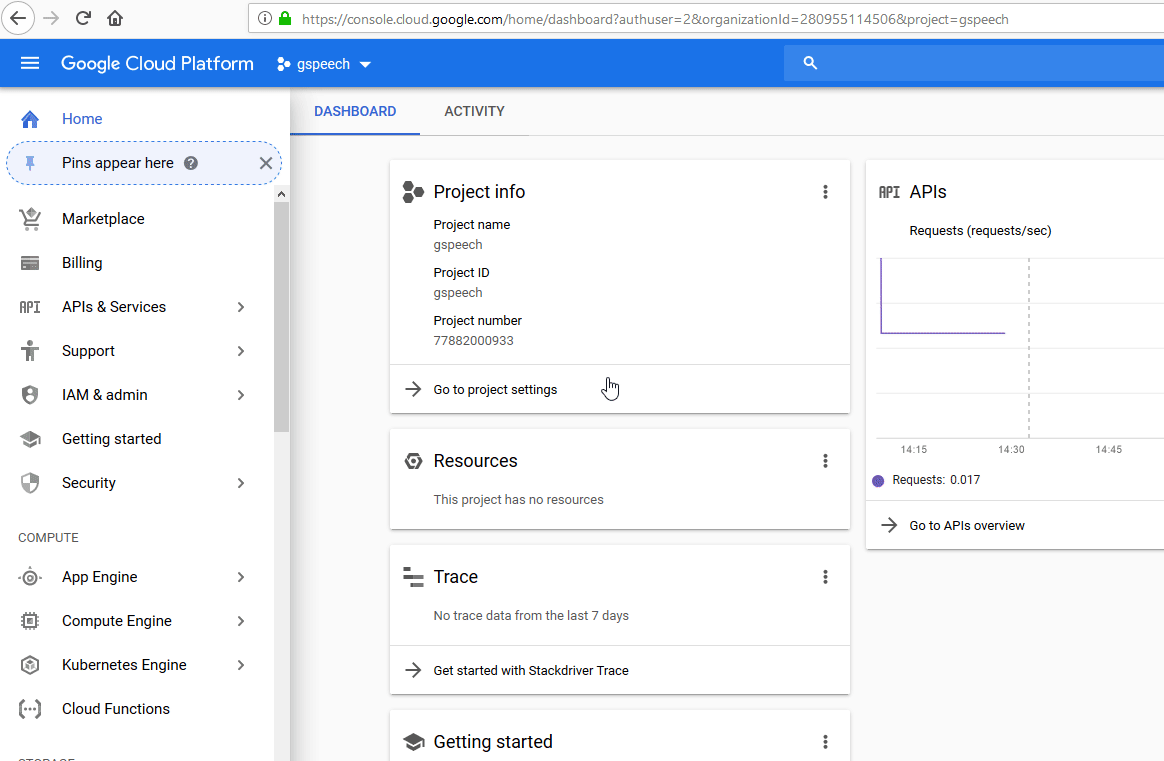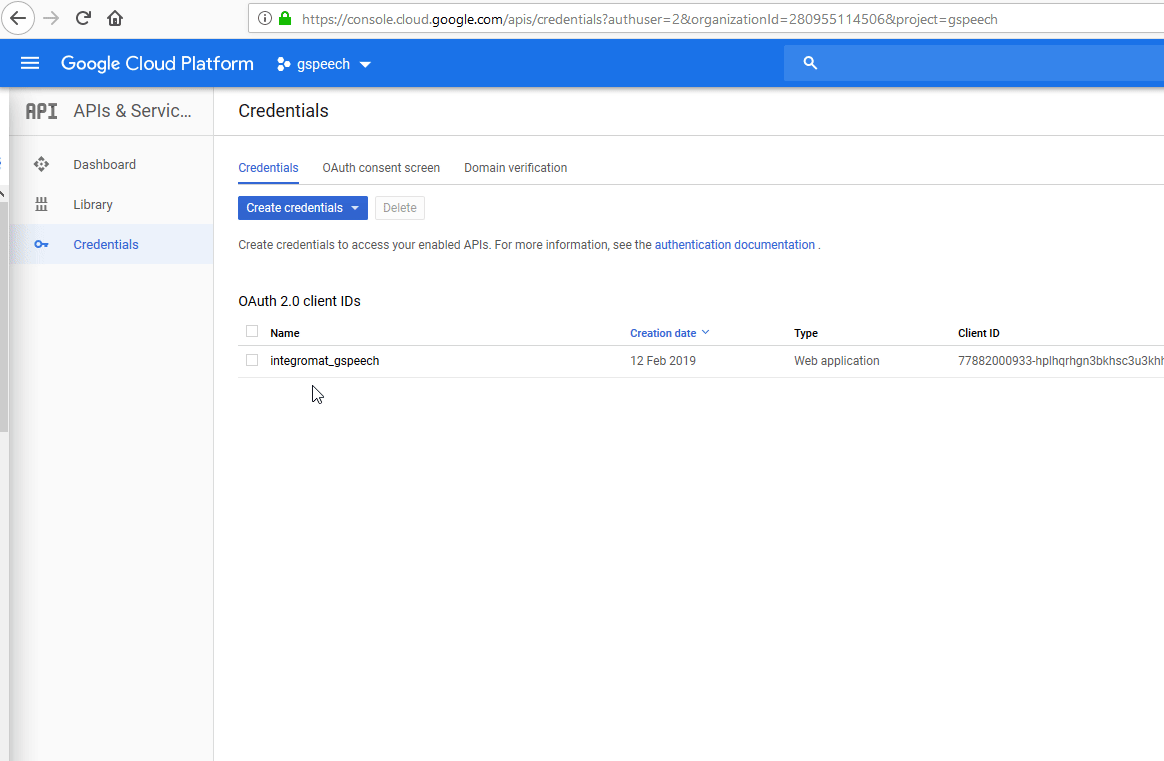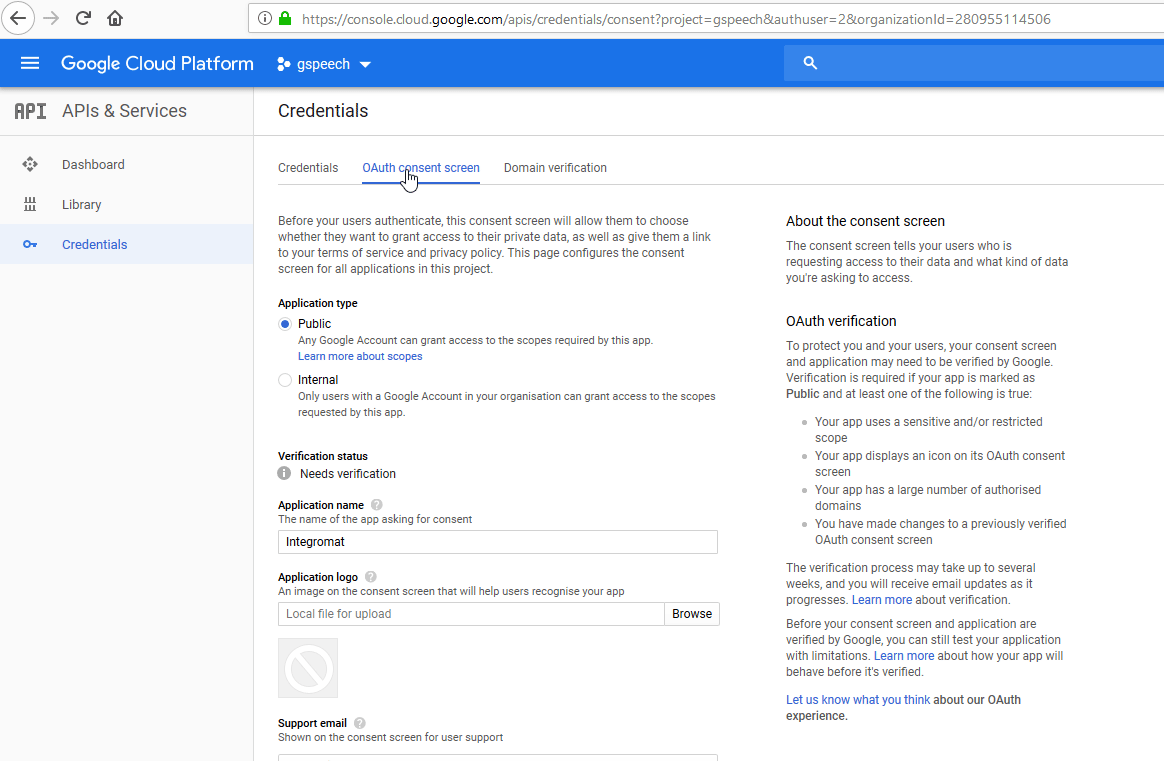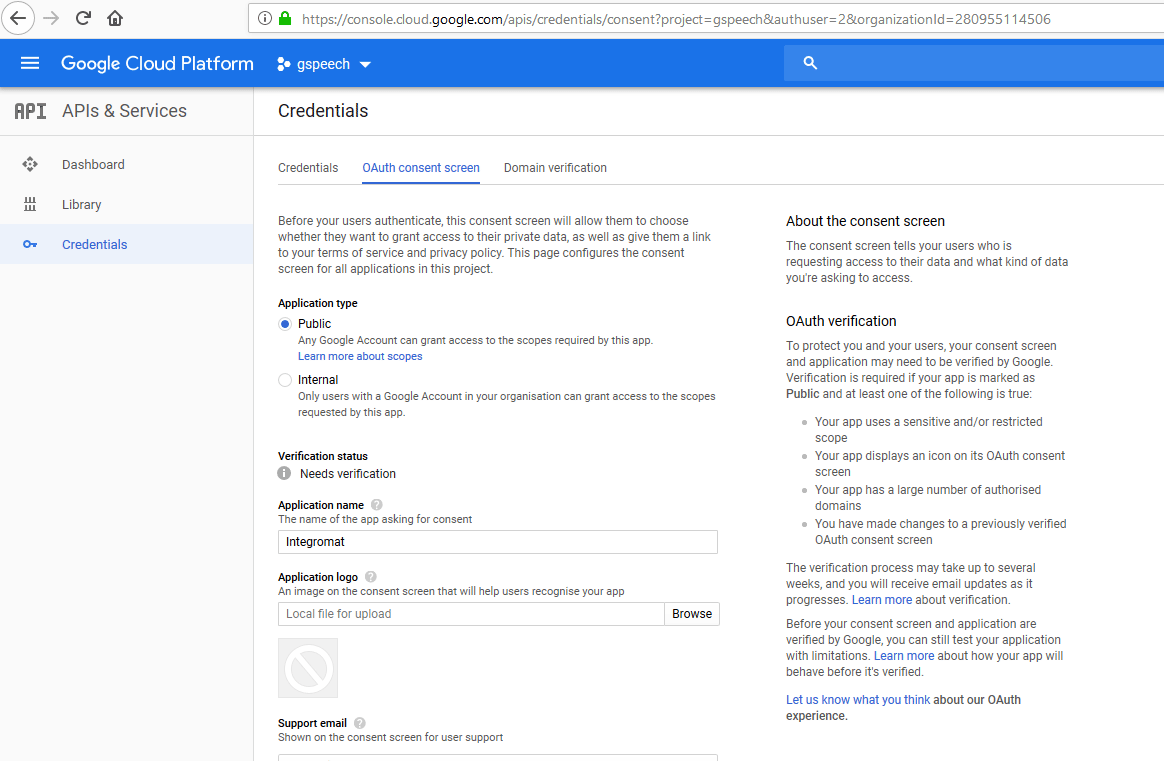
-
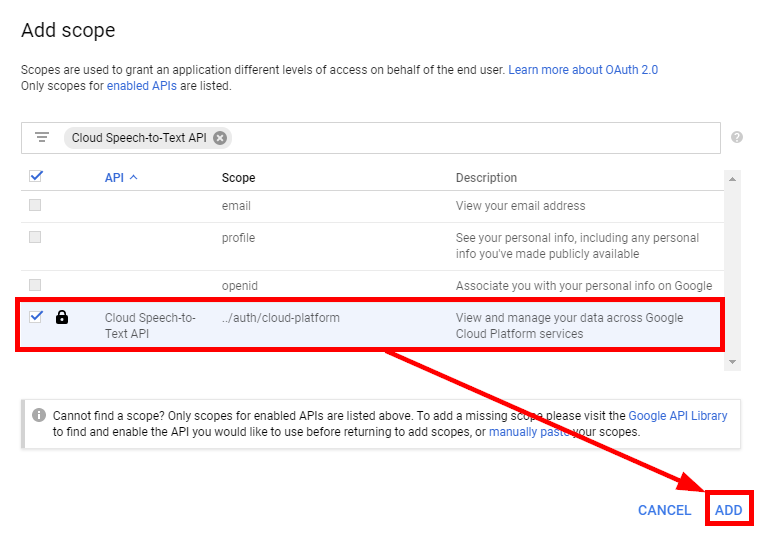
Click the Add Scope button to add a scope.
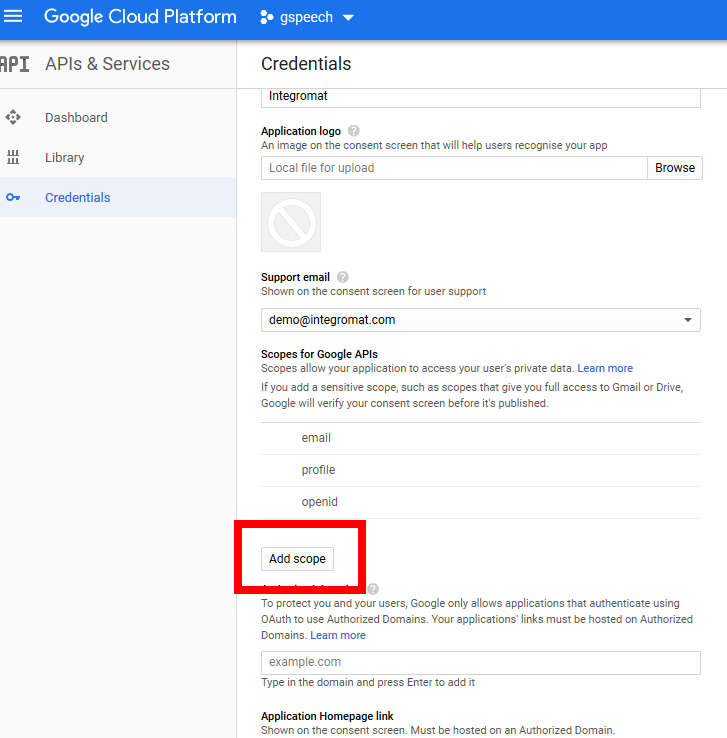
-
Add the Cloud Speech-to-Text API (https://www.googleapis.com/auth/cloud-platform) in the Add scope dialog.
Note
If there is no Cloud Speech-to-Text API scope in the Add scope dialog you must enable the scope in the Google API Library first.
-
Add
make.comto the Authorized domains field.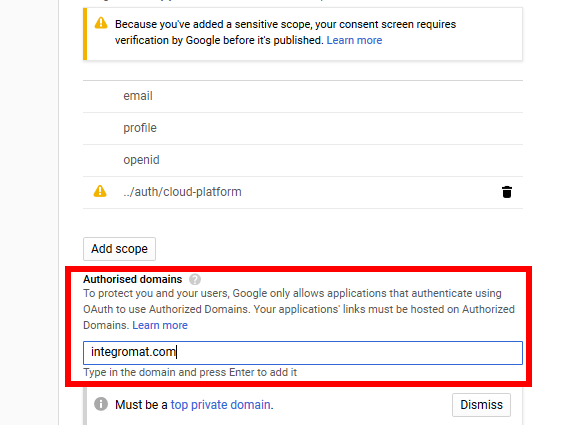
-
Click on the Save button to save the OAuth consent screen dialog.
-
Create the OAuth client ID. Use
https://www.integromat.com/oauth/cb/google-cloud-speechas a redirect URI.
-
Now, you can copy the Client ID and the Client Secret from the following dialog.
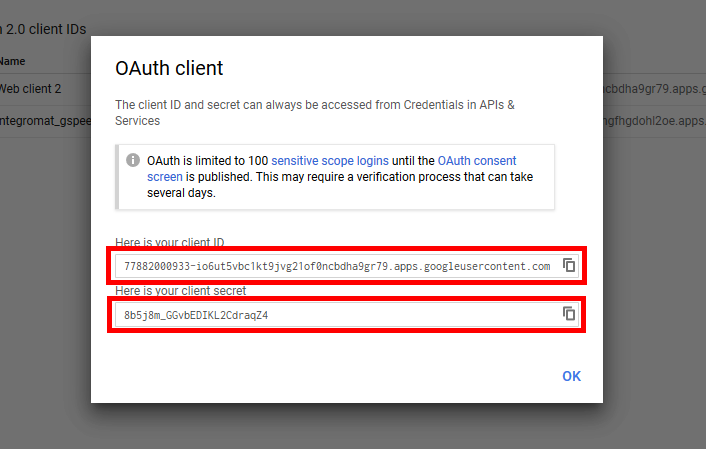
Connecting Google Speech Cloud to Ibexa Connect¶
-
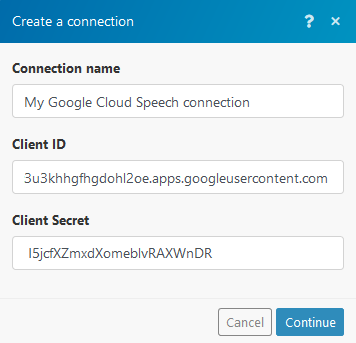
Open the Create a connection dialog.
-
Insert the Client ID and Client Secret.
-
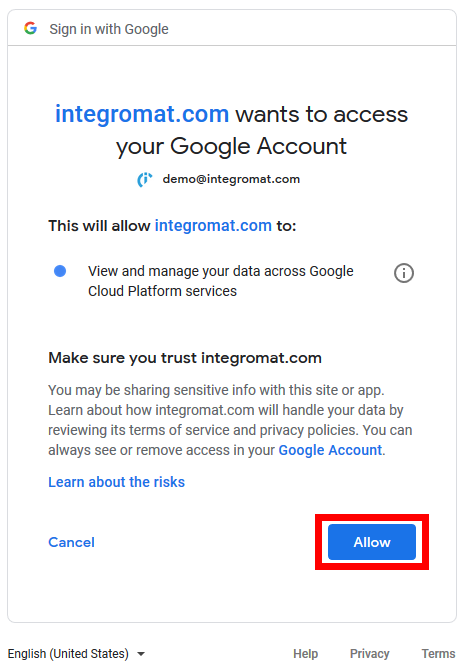
Grant access to your Google Account.
Enabling the Cloud Speech to Text Service¶
In order to start using the Google Cloud Speech module, it is necessary to enable the Cloud Speech to Text service.
-
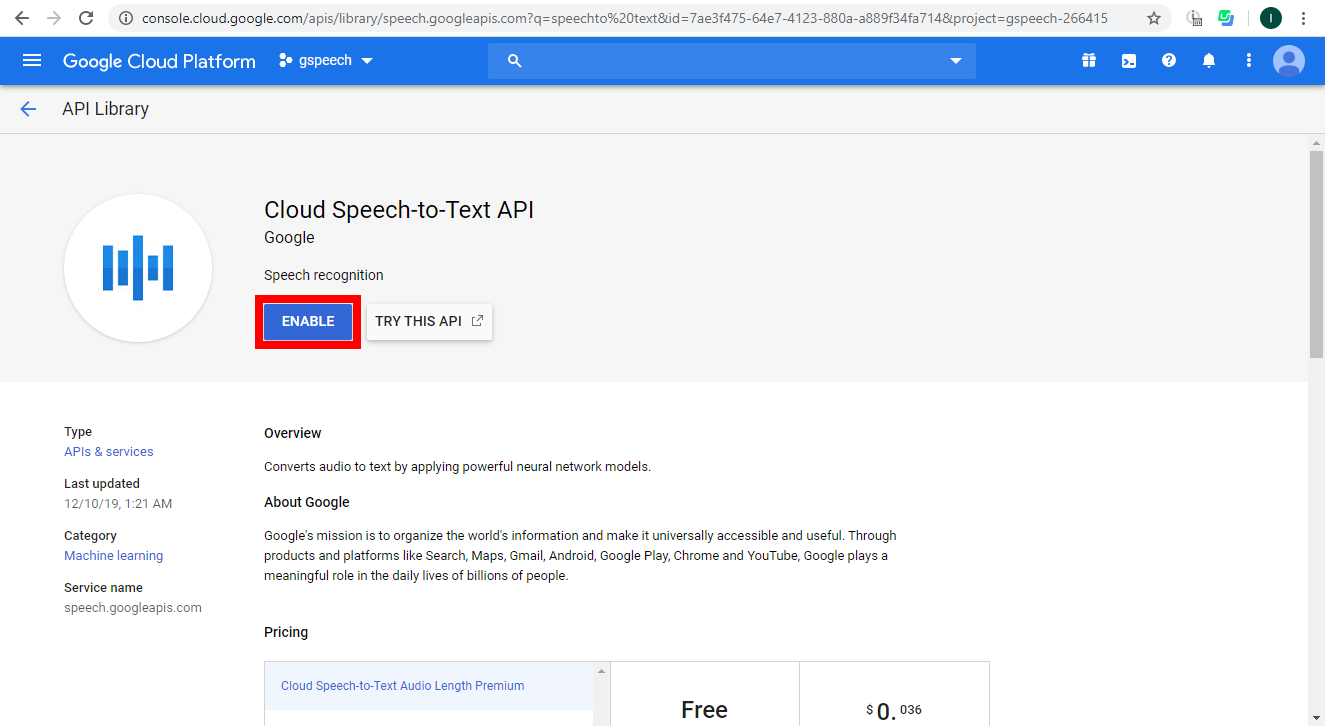
Go to APIs & Services > Library.
-
Search for Cloud Speech-to-Text API.
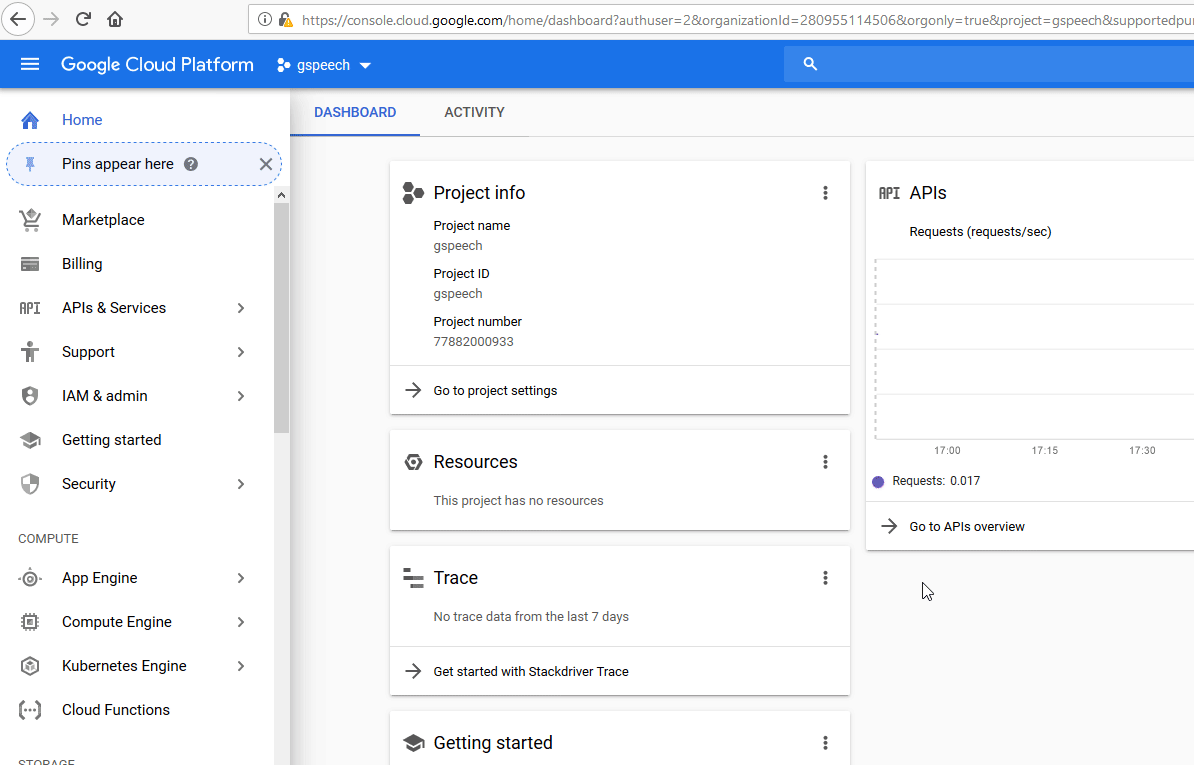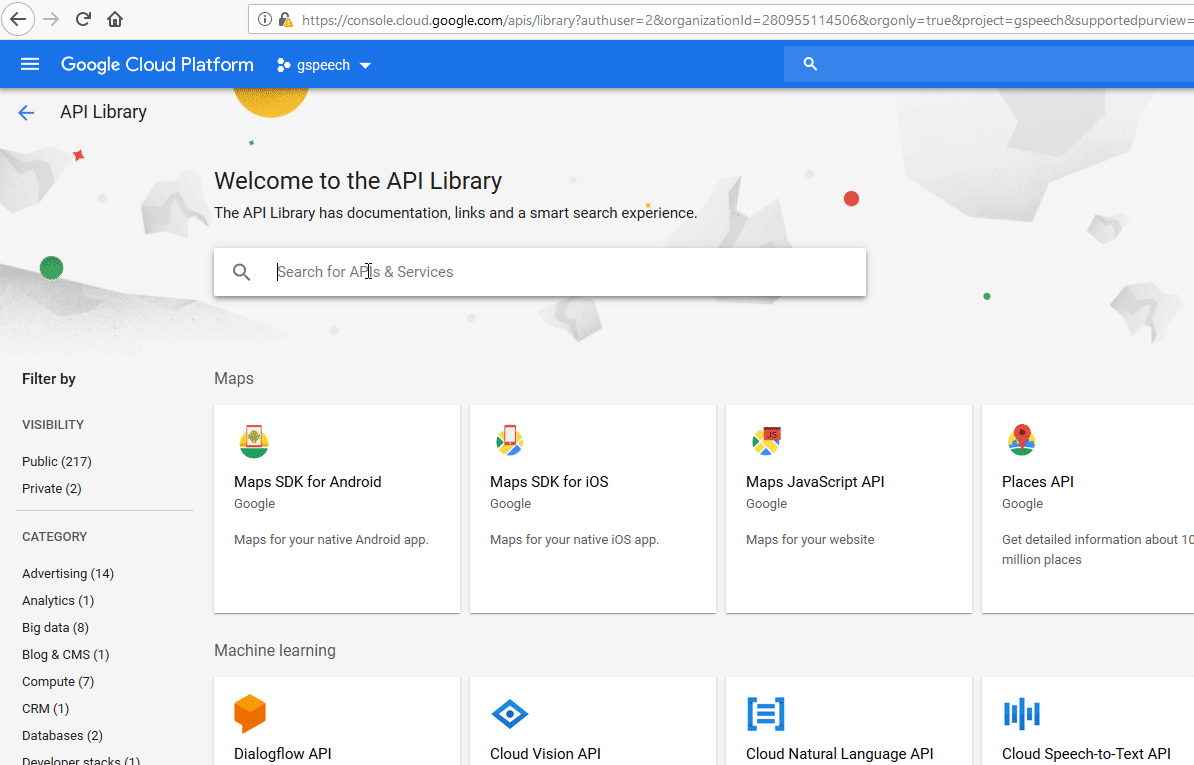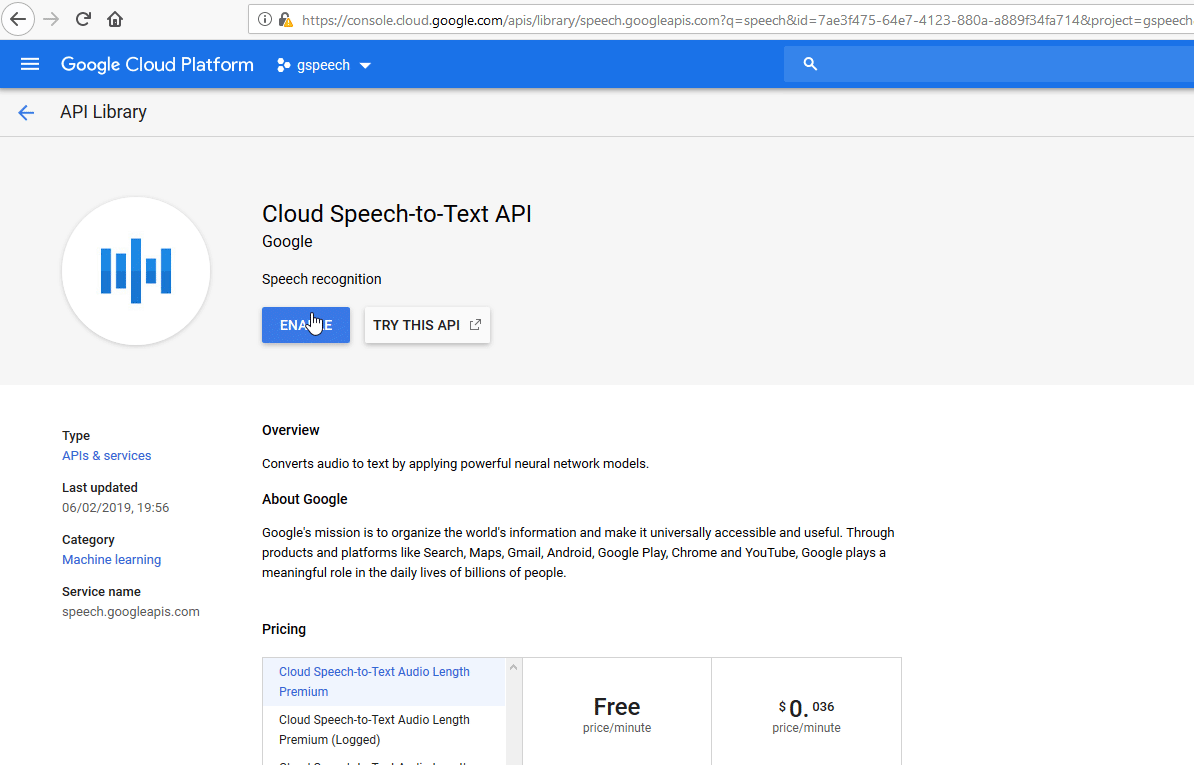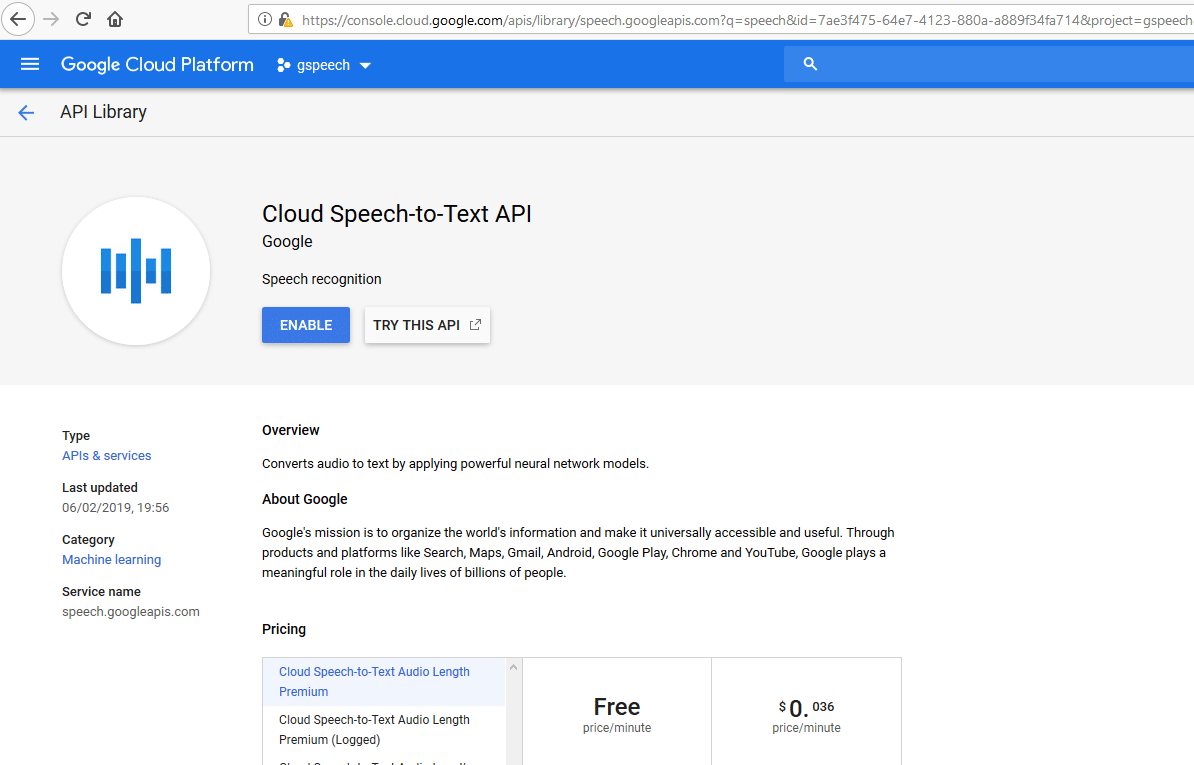
-
Enable Cloud Speech-to-Text API.
Actions¶
Speech: Long Running Recognize¶
Transcribes long audio files (longer than 1 minute) to text using asynchronous speech recognition. The name of the recognized file is provided. The module Google Cloud Speech > Operation: Get is then needed to retrieve the recognized text.
Note
The maximum file size for recognition is 10 485 760 bytes.
Source file |
Map the audio file you want to convert to text. If left empty the File URI must be provided. This field is mandatory. |
||
File URI |
URI that points to the file that contains audio data. The file must not be compressed (for example, gzip). Currently, only Google Cloud Storage URIs are supported, which must be specified in the following format: |
||
Audio Channels Count |
Enter the number of the audio file channels. ONLY set this for MULTI-CHANNEL recognition. Valid values for LINEAR16 and FLAC are | The module only recognizes the first channel by default. To perform independent recognition on each channel, enable the Enable separate recognition per channel option. |
Enable separate recognition per channel
Enable this option and set the Audio Channels Count to more than 1 to get each channel recognized separately. The recognition result will contain a *channelTag*field to state which channel that result belongs to. If this option is disabled, the module will only recognize the first channel.
Caution
The request is also billed cumulatively for all channels recognized: (Audio Channels Count times the audio length)
Language Code (BCP-47)
Enter the language code. The language of the supplied audio as a BCP-47 language tag. Example: "en-US". See Language Support for a list of the currently supported language codes. You can use BCP-47 validator. This field is mandatory.
Additional language tags
Add more language codes if needed. See Language Support for a list of the currently supported language codes. If alternative languages are listed, recognition result will contain recognition in the most likely language detected including the main Language Code. The recognition result will include the language tag of the language detected in the audio.
Note
This feature is only supported for Voice Command and Voice Search use cases and performance may vary for other use cases (e.g., phone call transcription).
Audio Encoding
Select the encoding of the audio file/data. For best results, the audio source should be captured and transmitted using a lossless encoding (FLAC or LINEAR16). The accuracy of speech recognition can be reduced if lossy codecs are used to capture or transmit audio, particularly if background noise is present. Lossy codecs include MULAW, AMR, AMR_WB, OGG_OPUS, and SPEEX_WITH_HEADER_BYTE.
ENCODING_UNSPECIFIED |
Not specified. |
LINEAR16 |
Uncompressed 16-bit signed little-endian samples (Linear PCM). |
FLAC |
FLAC (Free Lossless Audio Codec) is the recommended encoding because it is lossless--therefore recognition is not compromised--and requires only about half the bandwidth of LINEAR16. FLAC stream encoding supports 16-bit and 24-bit samples, however, not all fields in STREAMINFO are supported. |
MULAW |
8-bit samples that compand 14-bit audio samples using G.711 PCMU/mu-law. |
AMR |
Adaptive Multi-Rate Narrowband codec. sampleRateHertz must be 8000. |
AMR_WB |
Adaptive Multi-Rate Wideband codec. sampleRateHertz must be 16000. |
OGG_OPUS |
Opus encoded audio frames in Ogg container (OggOpus). sampleRateHertz must be one of 8000, 12000, 16000, 24000, or 48000. |
SPEEX_WITH_HEADER_BYTE |
Although the use of lossy encodings is not recommended, if a very low bitrate encoding is required, OGG_OPUS is highly preferred over Speex encoding. The Speex encoding supported by Cloud Speech API has a header byte in each block, as in MIME type audio/x-speex-with-header-byte. It is a variant of the RTP Speex encoding defined in RFC 5574. The stream is a sequence of blocks, one block per RTP packet. Each block starts with a byte containing the length of the block, in bytes, followed by one or more frames of Speex data, padded to an integral number of bytes (octets) as specified in RFC 5574. In other words, each RTP header is replaced with a single byte containing the block length. Only Speex wideband is supported. sampleRateHertz must be 16000. |
Sample rate in Hertz
Enter the sample rate in Hertz of the audio data. Valid values are 8000-48000. 16000 is optimal. For best results, set the sampling rate of the audio source to 16000 Hz. If that's not possible, use the native sample rate of the audio source (instead of re-sampling). This field is optional for FLAC and WAV audio files and required for all other audio formats.
Number of alternatives
The maximum number of recognition hypotheses to be returned. Valid values are 0-30. A value of 0 or 1 will return a maximum of one. If omitted, it will return a maximum of one. This field is optional.
Profanity filter
If this option is enabled, the server will attempt to filter out profanities, replacing all but the initial character in each filtered word with asterisks, e.g. "f***". If this option is disabled, profanities won't be filtered out. This field is optional.
Array of SpeechContexts
Enter "hints" to speech recognizer to favor specific words and phrases in the results. A list of strings containing word and phrase "hints" allows the speech recognition to more likely recognize them. This can be used to improve the accuracy for specific words and phrases, for example, if specific commands are typically spoken by the user. This can also be used to add additional words to the vocabulary of the recognizer. See usage limits.
Enable word time offsets
If this option is enabled, the top result includes a list of words and the start and end time offsets (timestamps) for those words. If this option is disabled, no word-level time offset information is returned. The option is disabled by default. This field is optional.
Enable word confidence
If this option is enabled, the top result includes a list of words and the confidence for those words. If this option is disabled, no word-level confidence information is returned. The option is disabled by default. This field is optional.
Enable automatic punctuation
If this option is enabled, it adds punctuation to recognition result hypotheses. This feature is only available in selected languages. Setting this for requests in other languages has no effect at all. The option is disabled by default. This field is optional.
Note
This is currently offered as an experimental service, complimentary to all users. In the future, this may be exclusively available as a premium feature.
Enable speaker diarization
This option enables speaker detection for each recognized word in the top alternative of the recognition result using a speakerTag provided in the WordInfo.
Diarization speaker count
Enter the estimated number of speakers in the conversation. If not set, defaults to '2'. Ignored unless Enable speaker diarization is enabled.
Metadata
Description of audio data to be recognized.
Interaction type |
The use case most closely describing the audio content to be recognized. |
Industry NAICS code of audio |
The industry vertical to which this speech recognition request most closely applies. This is most indicative of the topics contained in the audio. Use the 6-digit NAICS code to identify the industry vertical - see https://www.naics.com/search/. |
Microphone distance |
The audio type that most closely describes the audio being recognized. |
Original media type |
The original media the speech was recorded on. |
Recording device type |
The type of device the speech was recorded with. |
Recording device name |
The device used to make the recording. Examples 'Nexus 5X' or 'Polycom SoundStation IP 6000' or 'POTS' or 'VoIP' or 'Cardioid Microphone'. |
Original MIME type |
Mime type of the original audio file. For example audio/m4a, audio/x-alaw-basic, audio/mp3, audio/3gpp. A list of possible audio mime types is maintained at http://www.iana.org/assignments/media-types/media-types.xhtml#audio |
Obfuscated ID |
Obfuscated (privacy-protected) ID of the user, to identify the number of unique users using the service. |
Audio topic |
Description of the content. E.g. "Recordings of federal supreme court hearings from 2012". |
Model
Select the model best suited to your domain to get the best results.
command_and_search |
Best for short queries such as voice commands or voice search. |
phone_call |
Best for audio that originated from a phone call (typically recorded at an 8khz sampling rate). |
video |
Best for audio that originated from video or includes multiple speakers. Ideally, the audio is recorded at a 16khz or greater sampling rate. This is a premium model that costs more than the standard rate. |
default |
Best for audio that is not one of the specific audio models. For example, long-form audio. Ideally, the audio is high-fidelity, recorded at a 16khz or greater sampling rate. |
Enhanced
Enable this option to use an enhanced model for speech recognition. You must also set the model field to a valid, enhanced model. If the Enhanced option is enabled and the Model option is not selected, then the Enhanced option is ignored. If the Enhanced option is enabled and an enhanced version of the specified model does not exist, then the speech is recognized using the standard version of the specified model.
You must opt-in to the audio logging using the instructions in the data logging documentation.
Note
If you enable this option and you have not enabled audio logging, then you will receive an error.
Operations: Get¶
Retrieves the latest state or the result of a long-running operationlong-running operation. You can then use the result (text) in the following modules of your choice.
| Name | Enter the name of the operation. The name can be retrieved using the Speech: Long Running Recognize module.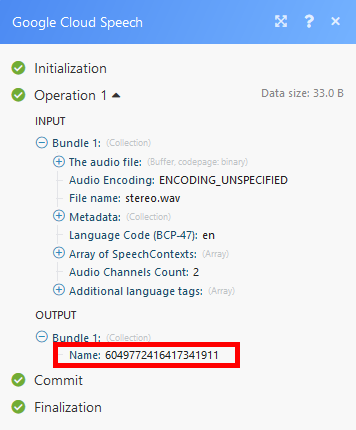  |
Searches¶
Speech: Recognize¶
This module returns the recognized text for short audio (less than ~1 minute). To process a speech recognition request for long audio, use the Speech: Long Running Recognize module.
The module Speech: Recognize contains the same options as the use the Speech: Long Running Recognize module.
The only difference is, that the recognition is done immediately. You do not need to use the Operations: Get module.
