Data export¶
You need to specify a source of the user data that Ibexa CDP connects to. To do so, go to Data Manager in Tools section and select Create new dataflow. It takes you to a Dataflow Creator, where in five steps you can set up a data streaming.
General Information¶
In the General Information section, specify dataflow name, choose Stream File as a source of user data and CDP as a destination, where they're sent for processing. Currently, only Stream File transport is supported and can be initialized from the configuration.
Download¶
In the Download section, select Stream file.
Copy generated steam ID and paste it into the configuration file under stream_id.
It allows you to establish a datastream from the Streaming API into the Data Manager.
Next, you need to export your data to the CDP. Go to your installation and use this command:
- for User:
1 | |
- for Product:
1 | |
- for Content:
1 | |
There are two versions of this command --draft/--no-draft.
The first one is used to send the test user data to the Data Manager.
If it passes a validation test in the Activation section, use the latter one to send a full version.
You can extend exported user data with custom fields from your user content, such as date of birth, preferences, or other profile information. For more information, see Data customization.
Next, go back to Ibexa CDP and select Validate & download. If the file passes, you can see a confirmation message. Now, you can go to the File mapping section.
File mapping¶
Mapping is completed automatically, the system fills all required information and shows available columns with data points on the right. You can change their names if needed or disallow empty fields by checking Mandatory. If the provided file contains empty values, this option isn't available.
If provided file isn't recognized, the system requires you to fill in the parsing-options manually or select an appropriate format. If you make any alterations, select the Parse File to generate columns with new data.
Transform & Map¶
In the Transform & Map section you transform data and map it to a schema. At this point, you can map email to email and id to integer fields to get custom columns.
If you have extended user data export with custom fields, those fields appear as additional columns in this section. Make sure to add them to your schema in Raptor so they can be used for segmentation and recommendations.
Next, select Create schema based on the downloaded columns. It moves you to Schema Creator. There, choose PersonalData as a parent and name the schema.
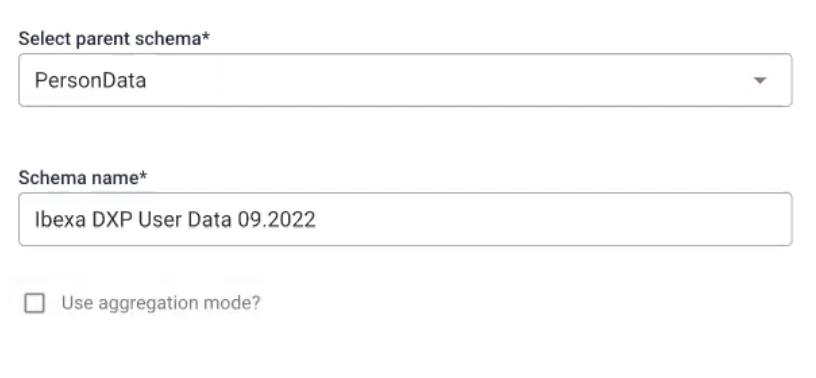
Next, select all the columns and set Person Identifier as userid.
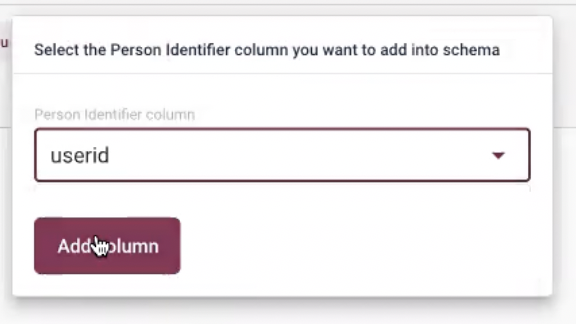
If you used PersonData or Catalog type schemas, the system requires specifying the Write Mode that is applied to them.
Append (default one) allows new data to overwrite the old one but leaves existing entries unaffected. All entries are stored in the dataset, unchanged by updating dataflow. For example, if a customer unsubscribes a newsletter, their email remains in the system. Overwrite completely removes the original dataset and replaces it with the new one every time the dataflow runs.
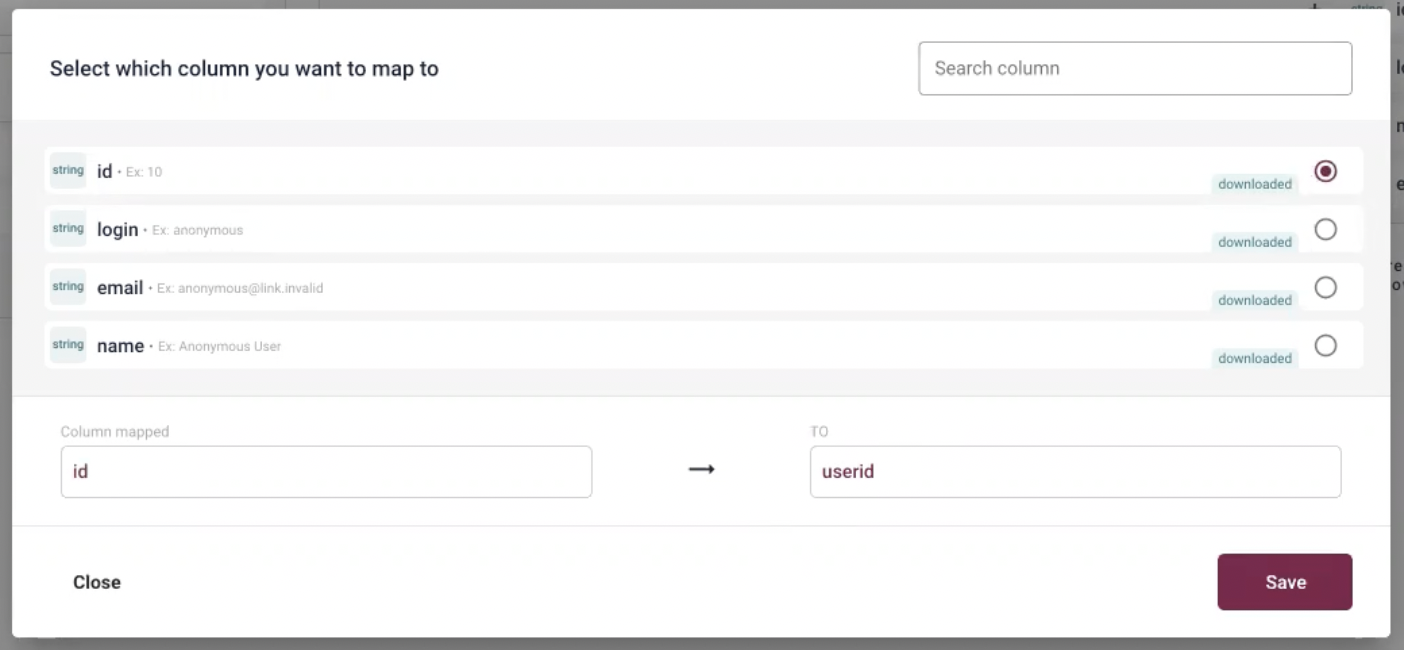
Next, select userid from a Schema columns section on the right and map it to id.
Activation¶
In this section you can test the dataflow with provided test user data. If everything passes, go to your installation and export production data with this command:
1 | |
Now you can run and activate the dataflow.
Build new Audience/Segment¶
Go to the Audience Builder and select Build new audience.
When naming the audience remember, you need to find it in a drop-down list during activation.
There, you can choose conditions from did, did not or have.
The conditions did and did not allow you to use events like buy, visit or add to a cart from online tracking.
haveconditions are tied to personal characteristics and can be used to track the sum of all buys or top-visited categories.
In the Audience Builder, you can also connect created audiences to the activations.
Activation¶
Activation synchronises data from Ibexa CDP to the Ibexa DXP. When you specify a segment, you can activate it on multiple communication channels, such as newsletters or commercials. You can configure multiple activations based data flows.
First, from the menu bar, select Activations and create a new Ibexa activation.
Specify name of your activation, select userid as Person Identifier and click Next.
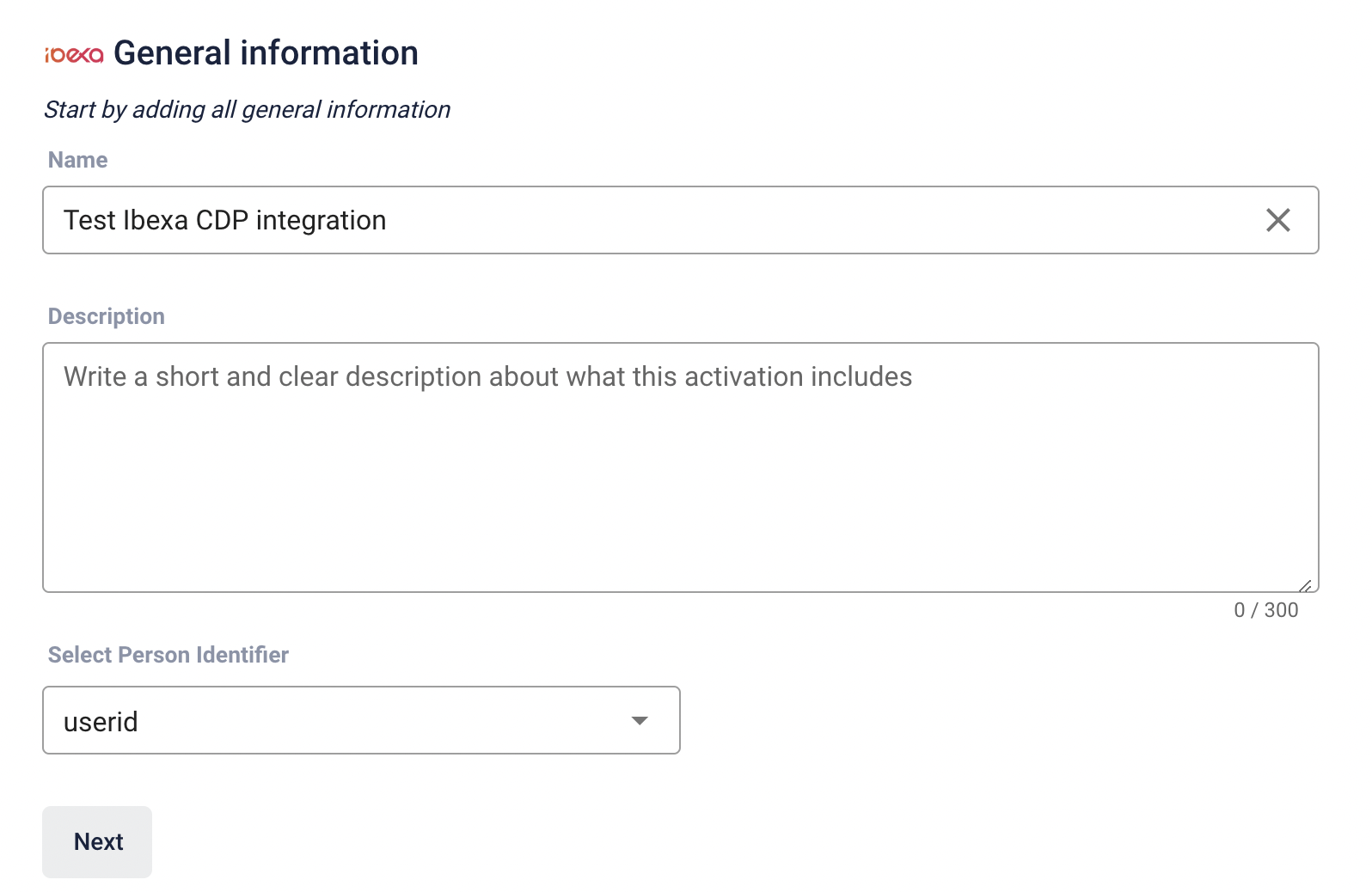
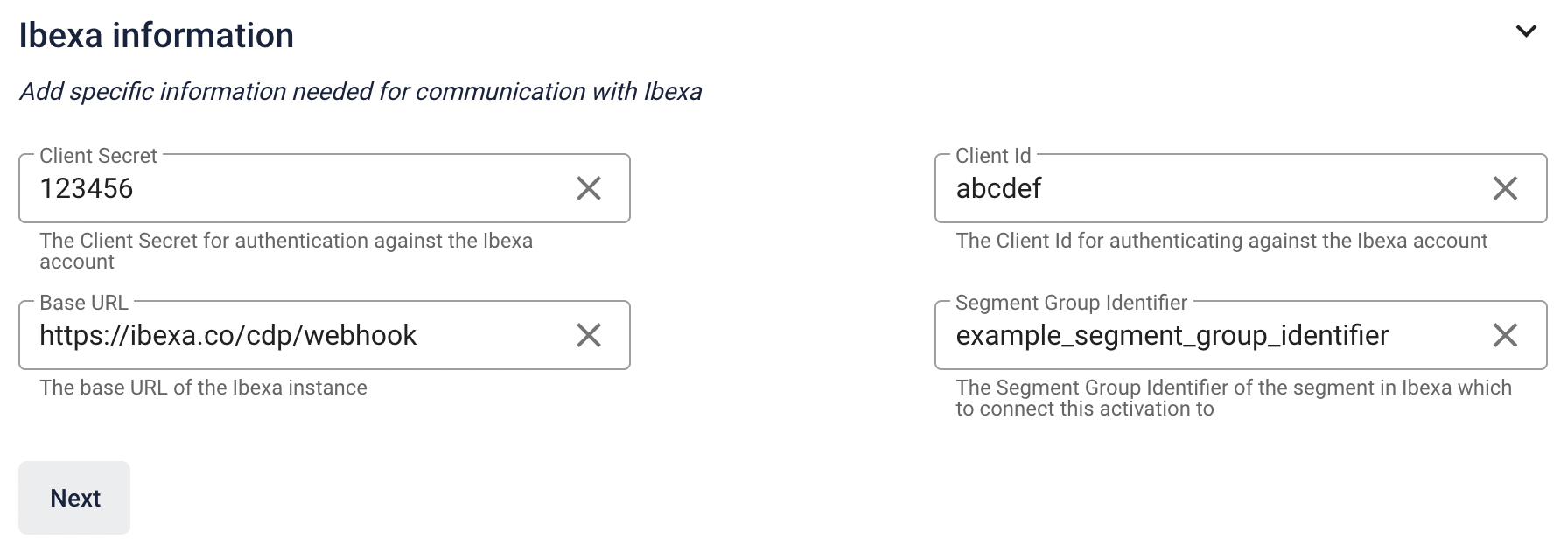
Next, you can fill in Ibexa information they must match the ones provided in the YAML configuration:
-
Client Secret and Client ID - are used to authenticate against Webhook endpoint. In the configuration they're taken from environment variables in
.envfile. -
Segment Group Identifier - identifier of the segment group in Ibexa DXP. It points to a segment group where all the CDP audiences are stored.
-
Base URL - URL of your instance with added
/cdp/webhookat the end.
Finally, you can specify the audiences you wish to include.
CDP requests
All CDP requests are logged in with debug severity.
Ibexa Messenger support for large batches of data¶
CDP uses Ibexa Messenger to process incoming data from Raptor. This approach improves performance and reliability when processing large amounts of CDP user records. For more information, see Background tasks: How it works.
By using Messenger while working with large batches of data, requests are queued instead of being processed synchronously:
- queuing items starts automatically once a certain number of actions is reached (below this number, items are processed in a single request, using the standard synchronous behavior)
- every single data is recorded in the database
- a background worker retrieves records from the queue, processing them one by one or in batches, depending on the Messenger configuration
- processing happens at set intervals to avoid timeouts and keep the system stable
1. Make sure that the transport layer is defined properly in Ibexa Messenger configuration.
2. Add bulk_async_threshold setting in the config/packages/ibexa_cdp.yaml configuration:
1 2 | |
Available options:
bulk_async_threshold(integer, default: 100) - minimum number of items required to trigger asynchronous processing- below threshold - items are processed immediately in a single request, using the standard synchronous behavior
- at/above threshold - items are automatically dispatched to the asynchronous queue for background processing
3. Make sure that the worker starts together with the application to watch the transport bus:
1 | |
For more information, see Start background task worker.
CDP Monolog channel¶
CDP Monolog channel handles webhook logs for easier separation of logs.
1 | |
It's possible to configure ibexa.cdp.webhook Monolog channel to direct all logs to specific stream, file, or service.
This allows webhook logs to be stored separately from the main application logs for easier debugging and analysis.
To do it, in config/packages/monolog.yaml file, define a new handler for the ibexa.cdp.webhook channel that directs CPD Webhook events to a separate file.
It can be configured in both dev and prod environments, for example:
1 2 3 4 5 6 7 | |
If you want to avoid redundant or duplicate entries in the other logs, exclude the webhook channel by:
1 | |